Au cœur de la révolution du SEO & de l’Intelligence Artificielle (AIO/GEO) se trouve une architecture clé qui vise à rendre les IA plus fiables et factuelles : la Retrieval-Augmented Generation (RAG).
Ancrer les LLM dans la réalité avec des données externes
La principale faiblesse d’un Large Language Model (LLM) est sa tendance à l’hallucination : il peut inventer des faits avec un aplomb déconcertant. Le Retrieval-Augmented Generation (RAG) est l’architecture dominante conçue pour résoudre ce problème. Son objectif est de connecter le LLM à une source de connaissances externe et à jour, pour l’ancrer dans la réalité et garantir la fiabilité et la traçabilité de ses réponses.Qu’est-ce que le RAG ? Le principe expliqué simplement
Le LLM seul : un cerveau brillant mais dans une pièce fermée
Imaginez un LLM comme un expert mondial enfermé dans une bibliothèque dont les livres n’ont pas été mis à jour depuis 2022. Sa connaissance est immense mais figée et sans contact avec le monde extérieur. Il ne connaît pas l’actualité et ne peut pas accéder à vos données d’entreprise.Le RAG : lui donner accès à une bibliothèque externe en temps réel
L’architecture RAG consiste à donner à ce cerveau une tablette connectée à une bibliothèque spécifique (le web, votre base de données interne, etc.) avant de lui poser une question. Il peut ainsi consulter les informations les plus récentes et les plus pertinentes avant de formuler sa réponse.Le processus en 3 étapes : requête -> recherche (retrieval) -> génération augmentée
Le fonctionnement de base est simple :-
Requête : L’utilisateur pose une question.
-
Recherche (Retrieval) : Le système ne transmet pas directement la question au LLM. Il l’utilise d’abord pour interroger une base de connaissances externe (souvent une base de données vectorielle) et en extraire les documents les plus pertinents.
-
Génération Augmentée : Le système envoie au LLM un nouveau prompt enrichi, qui contient à la fois la question originale ET les extraits des documents pertinents récupérés. Le LLM génère alors sa réponse en se basant sur cette source de vérité fournie.
[caption id=“attachment_2125” align=“alignnone” width=“800”]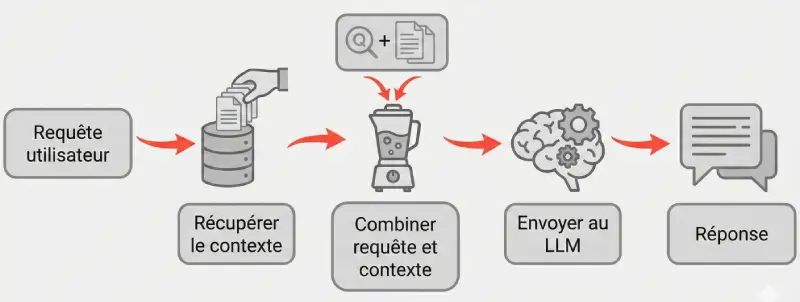 Flux RAG[/caption]
Flux RAG[/caption]
L’écosystème du RAG : panorama des techniques avancées
Le RAG de base a évolué vers de nombreuses architectures spécialisées, chacune visant à améliorer une partie du processus. Voici un panorama de ces techniques avancées.Auto-RAG et Self-RAG : Introduit dans un papier de recherche de l’Université de Washington, le Self-RAG est une approche où le LLM apprend à décider lui-même s’il a besoin de faire une recherche externe et à évaluer la qualité des sources récupérées. Il devient autonome dans son processus de vérification.
FLARE / Active RAG : Proposée notamment par Google DeepMind, cette méthode (Forward-Looking Active Retrieval) est plus dynamique. Le LLM commence à générer la réponse et, s’il anticipe une information manquante, il met la génération en pause pour effectuer une recherche ciblée avant de continuer.
Corrective RAG (CRAG) et Reliability-Aware RAG (RA-RAG) : Ces approches, comme le CRAG, se concentrent sur la fiabilisation. Elles intègrent un évaluateur qui note la pertinence des documents récupérés. Si les documents sont jugés de faible qualité, le système peut décider de chercher d’autres sources (par exemple sur le web) avant la génération.
GraphRAG : Développée par Microsoft Research, cette technique utilise un Knowledge Graph comme base de connaissances. Au lieu de chercher dans des morceaux de texte, le système navigue dans un graphe d’entités et de relations, ce qui permet un raisonnement beaucoup plus structuré et des réponses plus précises sur des sujets complexes.
HybridRAG et Multi-Fusion Retrieval (MoRAG) : Des architectures comme HybridRAG combinent plusieurs méthodes de recherche (par exemple, la recherche par mots-clés et la recherche sémantique vectorielle) pour améliorer la pertinence des résultats. Le MoRAG va plus loin en fusionnant des informations issues de plusieurs requêtes ou sources.
D’autres variantes émergent constamment, comme le Speculative RAG (lien du papier de recherche) qui utilise des modèles plus petits pour générer plusieurs brouillons de réponses en parallèle, qui sont ensuite vérifiés par un modèle plus grand.
Le RAG, la clé pour des IA génératives fiables et pertinentes
En conclusion, le Retrieval-Augmented Generation est bien plus qu’un simple acronyme technique. C’est la brique fondamentale qui permet de transformer les LLM d’oracles créatifs mais peu fiables en véritables moteurs de réponse factuels et sourcés. Comprendre les architectures RAG, c’est comprendre comment fonctionnent les moteurs de recherche de nouvelle génération et comment optimiser ses contenus pour devenir une source de confiance pour ces systèmes. Pour optimiser sa visibilité auprès des agents IA (Agentic SEO), l’enrichissement des données structurées est devenu un pilier, car c’est ce qui permet de transformer un contenu textuel classique en une base de connaissances exploitable par les algorithmes de RAG .Prêt à bâtir des stratégies basées sur ces architectures avancées ?
Comprendre et exploiter les architectures RAG est la prochaine frontière de la performance SEO. Discutons de la manière dont nous pouvons préparer votre contenu et votre stratégie à être les sources de confiance des moteurs de réponse de demain. Planifier une consultation GEOQuestions fréquemment posées (FAQ)
Quelle est la différence entre le RAG et le fine-tuning ?
Le fine-tuning consiste à ré-entraîner un LLM sur un jeu de données spécifique pour lui apprendre un style ou un domaine d’expertise. C’est comme apprendre une nouvelle compétence. Le RAG, lui, ne modifie pas le modèle ; il lui donne accès à des informations externes en temps réel. C’est comme lui donner un accès à une bibliothèque spécialisée. Les deux approches sont d’ailleurs souvent complémentaires.En quoi le RAG est-il important pour le SEO ?
Les moteurs de recherche modernes comme Google (avec les AI Overviews) et Perplexity utilisent des systèmes basés sur le RAG. Ils interrogent leurs index (le web) pour trouver les informations les plus pertinentes avant de générer une réponse de synthèse. Comprendre le RAG, c’est comprendre comment ces nouveaux moteurs “pensent” et donc comment optimiser son contenu pour être utilisé comme une source fiable.Rédigé par Benjamin Monnereau, expert en stratégies SEO & IA.
Ces sujets pourraient vous intéresser
 Les concepts fondamentaux de l’IA : le dictionnaire pour tout comprendreMaîtrisez le vocabulaire de l'IA. Découvrez les définitions simples du Machine Learning, NLP, LLM, Vector Search et autres concepts clés.
Les concepts fondamentaux de l’IA : le dictionnaire pour tout comprendreMaîtrisez le vocabulaire de l'IA. Découvrez les définitions simples du Machine Learning, NLP, LLM, Vector Search et autres concepts clés. Qu’est-ce qu’un LLM (Large Language Model) ? Le guide pour tout comprendreDécouvrez ce que sont les LLM (Large Language Models). Explorez le fonctionnement des cerveaux qui animent ChatGPT, Gemini et Claude.
Qu’est-ce qu’un LLM (Large Language Model) ? Le guide pour tout comprendreDécouvrez ce que sont les LLM (Large Language Models). Explorez le fonctionnement des cerveaux qui animent ChatGPT, Gemini et Claude. Prompting pour SEO : le guide pour transformer les LLM en assistants performantsMaîtrisez l'art du prompting pour le SEO. Apprenez à transformer les LLM en assistants performants pour vos tâches quotidiennes.
Prompting pour SEO : le guide pour transformer les LLM en assistants performantsMaîtrisez l'art du prompting pour le SEO. Apprenez à transformer les LLM en assistants performants pour vos tâches quotidiennes. Techniques de prompting : le guide avancé pour maîtriser les LLMExplorez les techniques de prompting avancées (Chain-of-Thought, Tree of Thought...). Décuplez la puissance des LLM pour vos analyses.
Techniques de prompting : le guide avancé pour maîtriser les LLMExplorez les techniques de prompting avancées (Chain-of-Thought, Tree of Thought...). Décuplez la puissance des LLM pour vos analyses.